 BxBFFT for Xilinx Ultrascale/Ultrascale+
BxBFFT for Xilinx Ultrascale/Ultrascale+
BxBFFT for Xilinx Ultrascale/Ultrascale+
BxBFFT for Xilinx Ultrascale/Ultrascale+
The BxBFFT is an amazing high-speed streaming Fast Fourier Transform, and the Xilinx Ultrascale/Ultrascale+ was its first supported FPGA family. The BxBFFT has all the advantages specified on the main BxBFFT page, plus additional advantages specific to the Ultrascale/Ultrascale+ that are documented on this page.
It is not uncommon for an FPGA design to approach either power limits or resource limits. Even when this is not true of a baseline design, it often becomes true because of the introduction of new product features. Power consumption of an FFT can thus make or break a design, or allow or disallow product upgrades. Power consumption also affects product life and reliability, as high consumption puts extra stress on the power supply, and high temperatures and large temperature swings increase the rate of component degradation. High-speed FFTs require intensive processing, and thus may use a large percentage of the total power consumption of a design. Thus power reduction in the FFT can be of particularly high importance.
The BxBFFT is highly optimized for power consumption. Multiple customers have found that a switch to the BxBFFT saved significant amounts of power in their designs, making those designs viable where before they were not.
Below are results from Xilinx Vivado synthesis for power consumption of the BxBFFT vs several other FFTs. It shows that BxBFFT power is typically lower than other FFTs by a factor of 1.5X to 2X in Ultrascale/Ultrascale+ FPGAs.

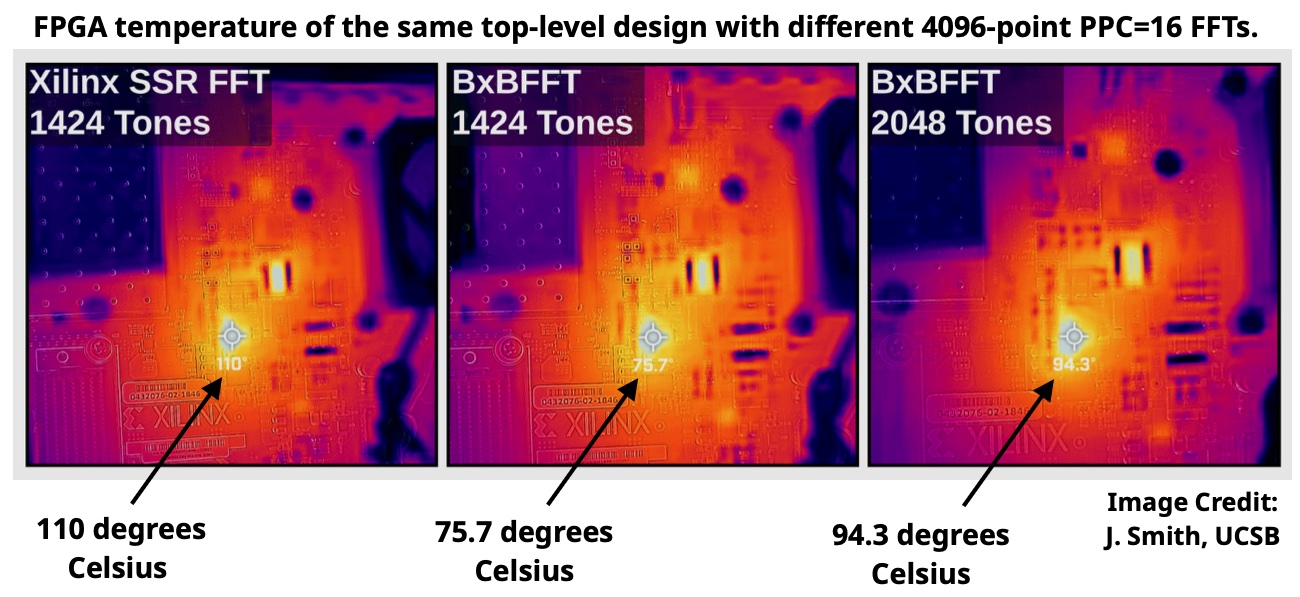
The thermal image below was taken by a customer, J. Smith of UCSB, showing how BxBFFT power is lower in a real-world design. Her design would not process the desired 2048 tones with the Xilinx SSR FFT; only 1424 could be processed before the chip would reset itself from excess current draw. Replacing the Xilinx SSR FFT with a BxBFFT lowered the die temperature from 110 degrees to 75.7 degrees Celsius when running the 1424 tones -- a drop of 34.3 degrees!! The design then worked properly with the full load of 2048 tones.
FPGA resources are another common design limitation. Designs that use fewer resources have more margin for initial implementation and for future upgrades. For the same design, they can use fewer FPGAs of smaller size and be cheaper to manufacture. With fewer used resources, routing in the FPGA is easier and thus it is easier to meet timing at higher clock speeds.
The BxBFFT uses substantially fewer FPGA LUTs than competing FFTs in Ultrascale/Ultrascale+ FPGAs, as shown in the graph below.

The DSPs required by the BxBFFT are among the lowest of all FFTs, with some FFTs taking 2, 3, or even 5 times more DSPs than the BxBFFT.

For large FFTs where memory is most critical, the BxBFFT has an option to save memory by autogeneration of twiddle coefficients rather than storing them in ROM. The BxBFFT also offers an option to save memory for the case where a scrambled output data order is acceptable. In addition, the BxBFFT has options to control tradeoffs between placing memories in BRAMs, UltraRAMs, or distributed LUT memory. All graphs are for default options.

Sometimes designs need to meet strict real-time requirements, either in throughput or in latency. Both of these improve when an FFT runs faster. A faster FFT can be achieved with a higher achieved FPGA clock rate (Fmax) or with increased parallelism. Parallelism is measured by the processed complex data Points Per Clock (PPC), also called SuperSample Rate (SSR). Throughput is Fmax * PPC.
One issue is that as PPC increases, more resources are used, there is more resource contention, and thus the achieved Fmax of an FFT goes down. This may make the desired throughput unachievable.
Fmax degrades less from resource contention for BxBFFTs than for other FFTs. BxBFFTs are thus able to achieve higher throughput, because a high Fmax and high PPC are simultaneously achievable. The graph below shows this. The BxBFFT achieves high PPC and high Fmax simultaneously, when the other FFTs do not. Thus the BxBFFT provides the best throughput and latency.

The BxBFFT was designed to get you running quickly. It has features to make configuration, synthesis, and simulation faster and easier, saving NRE. Many of these features are mentioned on the main BxBFFT page. There are a few productivity features specific to Xilinx FPGAs.
One productivity feature specific to Xilinx FPGAs is the inclusion of a Xilinx "IP Integrator" model. This allows quick integration of the BxBFFT with Xilinx IP. Most major BxBFFT features are controllable from a GUI selection box with this approach. This allows extreme ease-of-use.
For those using Xilinx block designs, this is the fastest way to instantiate and configure a BxBFFT.
BxBFFTs are faster in Xilinx Vivado implementation than competitors, which can save significant engineering time during product development. In part this is because BxBFFT code is written in a SystemVerilog style that is direct and easy to parse, which reduces time in Vivado synthesis.
Part of the savings is also in place and route, because BxBFFTs have more timing margin than competitors. This additional timing margin is what allows BxBFFTs to achieve high Fmax and thus high throughput. Timing margin also means that the Vivado place and route steps don't need to work as hard to meet desired timing constraints. As a result, Vivado implementation time is shorter.
The graph below shows how other FFTs take more implementation time than the BxBFFT. (Some FFTs are not yet shown because of a change in build machine speed that will require all FFT tests to be re-run for equal comparisons.)

These results illustrate how the BxBFFT is superior in most ways to other FFTs in Xilinx Ultrascale/Ultrascale+ FPGAs. It uses less power, uses fewer resources, and attains higher speeds. It is unmatched at almost all FFT sizes and speeds. It is unmatched in supported features. It is also cross-platform, supporting both Xilinx and Altera FPGAs, with a path into ASICs.